Improving Vision-Language-Action Model with Online Reinforcement Learning
本文最后更新于 2025年3月7日 下午
arxiv链接:
https://arxiv.org/pdf/2501.16664
Improving Vision-Language-Action Model with Online Reinforcement Learning

总结:使用RL finetune VLM 不稳定,这里感觉参考了replay buffer的想法,分为两步,先用RL 收集数据,只训action head,然后再用成功轨迹去finetune VLM, backbone 和action head都训练.
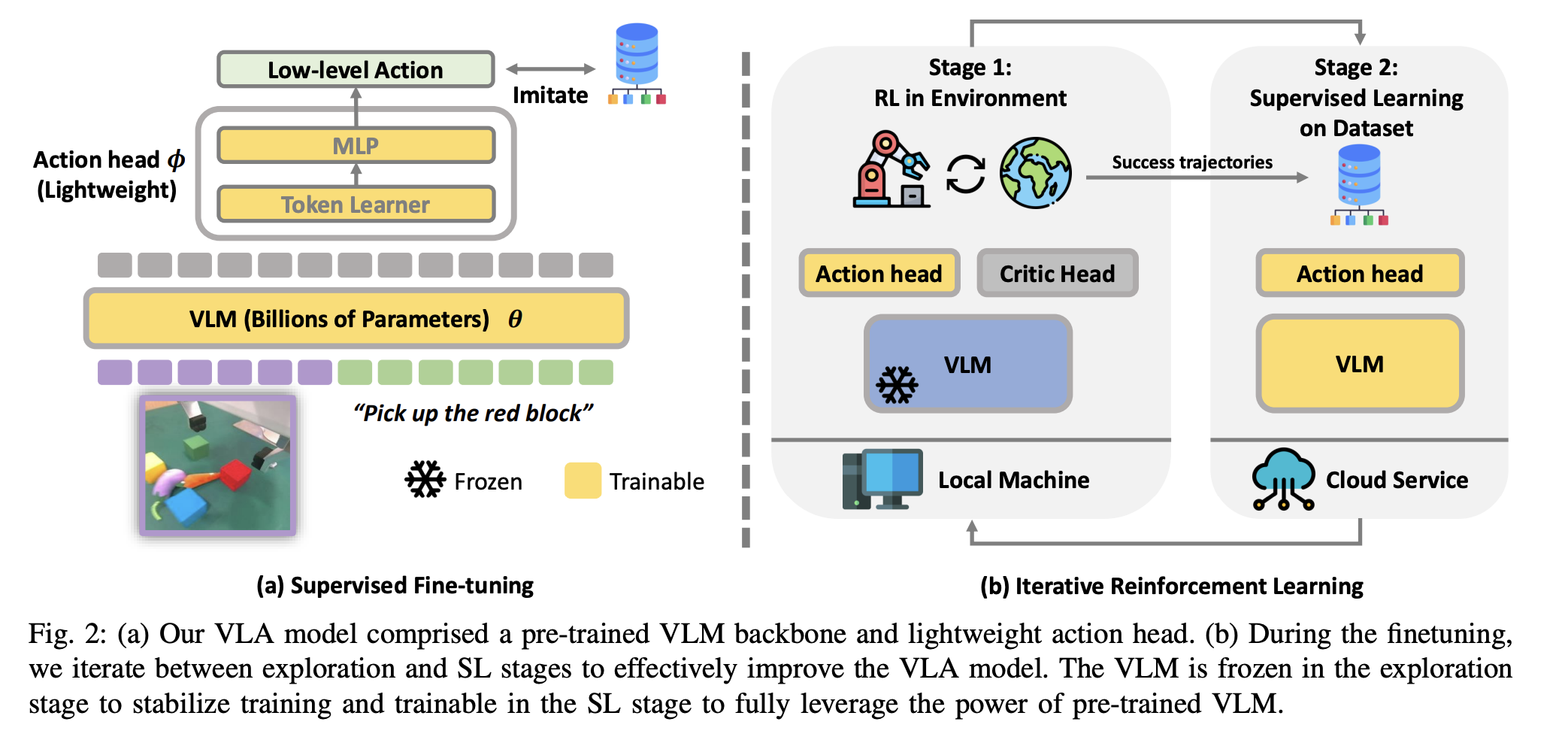
只用ppo replay效果不好, 结果: 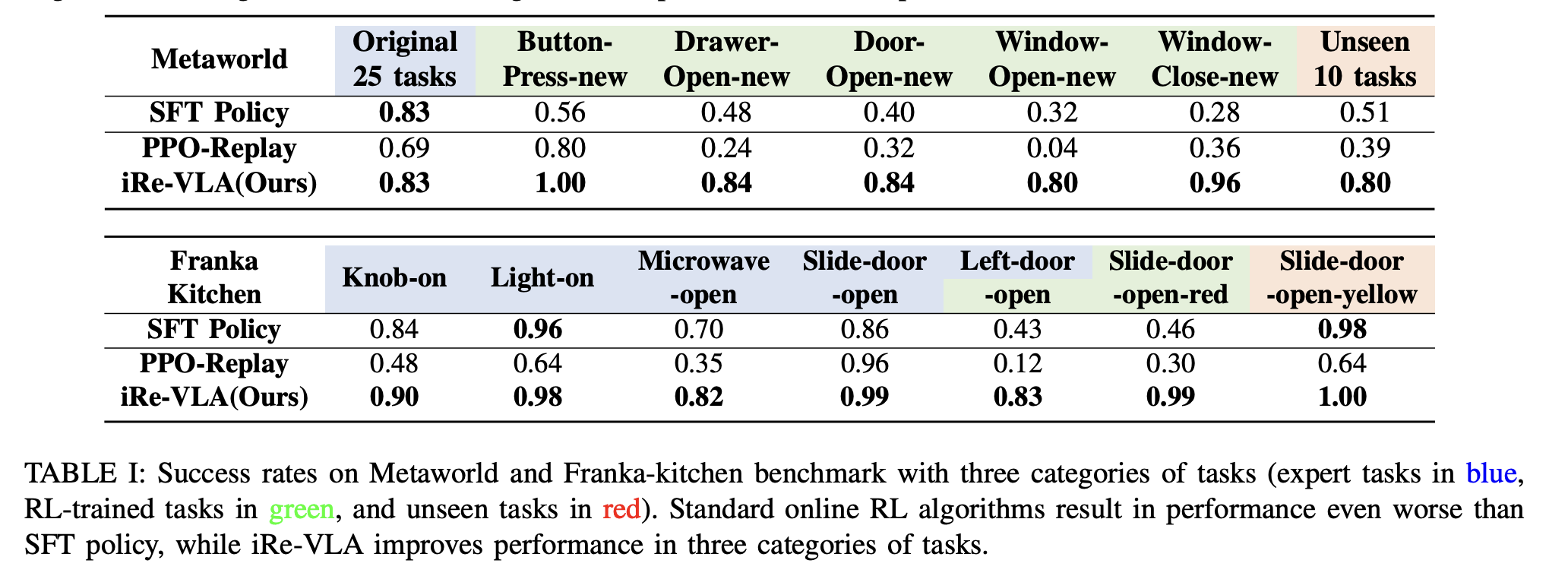
Improving Vision-Language-Action Model with Online Reinforcement Learning
http://example.com/2025/03/06/2025-3/paper3/