OTTER:A Vision-Language-Action Model with Text-Aware Visual Feature Extraction
本文最后更新于 2025年3月7日 下午
OTTER:A Vision-Language-Action Model with Text-Aware Visual Feature Extraction
加强VLA对语言的理解能力

A simple but efficient method
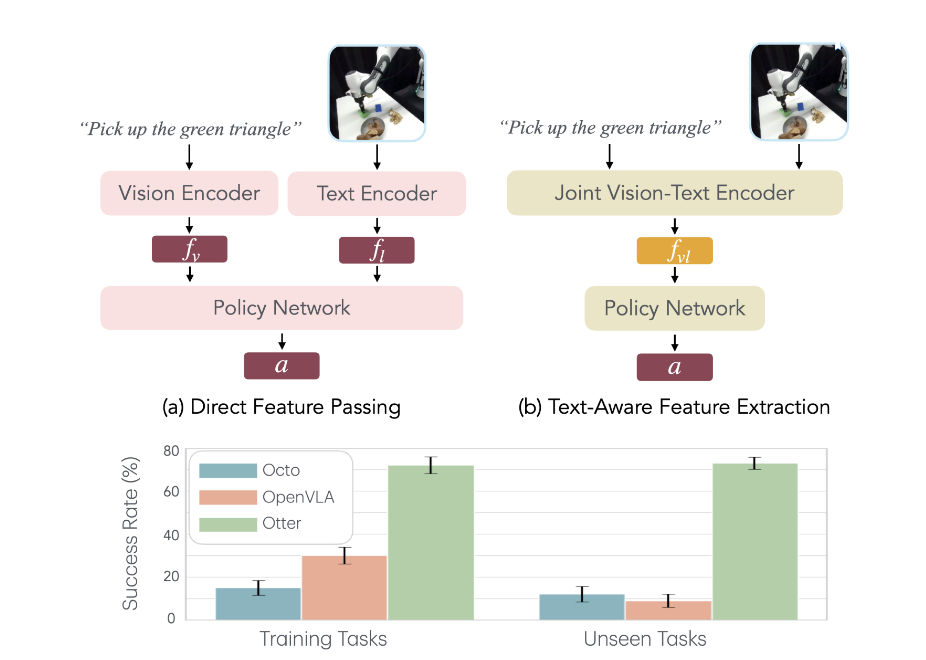
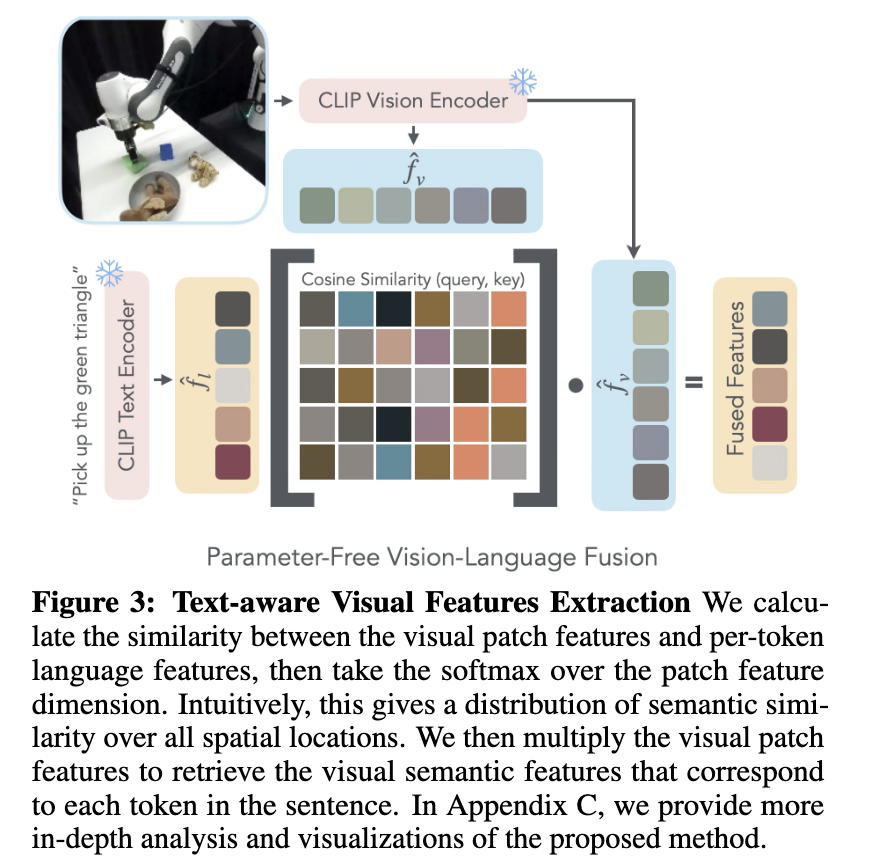
OTTER:A Vision-Language-Action Model with Text-Aware Visual Feature Extraction
http://example.com/2025/03/06/2025-3/paper4/